很多开发团队使用LLM的人最终都会遇到同样的瓶颈。
编写了详细的system prompt(系统提示),添加了few-shot examples(少量示例),调整了temperature(温度),但agent still仍然有 30-40% 的幻觉出错率。
麻烦的是!它从不从这些错误中吸取教训。

微调是突破瓶颈的关键。
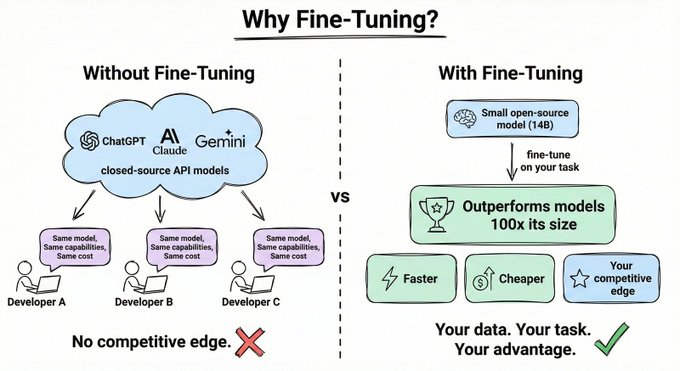
如果使用的是 GPT、DeepSeek或 Claude,那么使用的模型与其他人相同,功能相同,成本相同,没有任何竞争优势。
但是,如果使用一个小型开源模型,并针对特定任务进行微调呢?它的性能可以超过规模大100倍的模型,而成本和延迟却低得多。
大多数开发者都认为微调需要痛苦的设置:精心挑选的数据集(curated datasets)、标注的输出(labeled outputs)、手动设计的奖励函数(hand-crafted reward functions)。
现在2026年,情况就不同了。
使用 GRPO 和 RULER 的现代微调方法改变了AI智能体训练的格局。现在,可以训练出能够真正通过经验不断进步的智能体,而无需编写任何奖励函数或收集任何标注样本。
本AI笔记将详细介绍具体方法。
SFT与强化微调
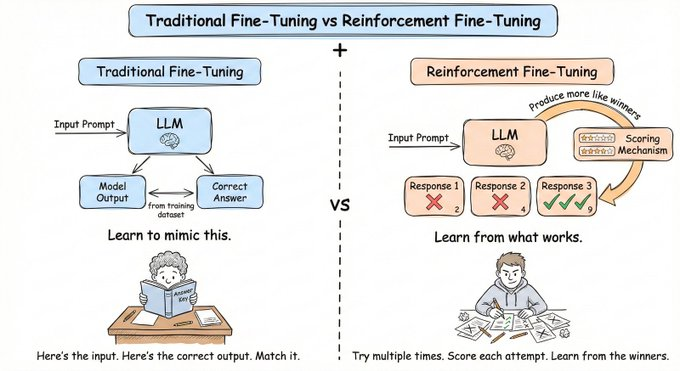
大多数开发者都了解监督式微调(SFT)。你收集输入输出对(input-output pairs),模型学习模仿它们。
问题是?SFT 教的是模型该说什么,而不是如何succeed。
对于需要进行搜索、调用 API 和跨多个步骤进行推理的Agents来说,模仿是不够的。你需要通过反复试验来不断改进。
换个角度想:
-
SFT = 学习教科书(记住已知问题的答案)
-
强化学习 = 在职培训(通过试错和反馈学习)
这就是强化微调(RFT)。给模型一个奖励信号,让它自己发现最佳策略。
GRPO 的工作原理
那背后的算法是什么?
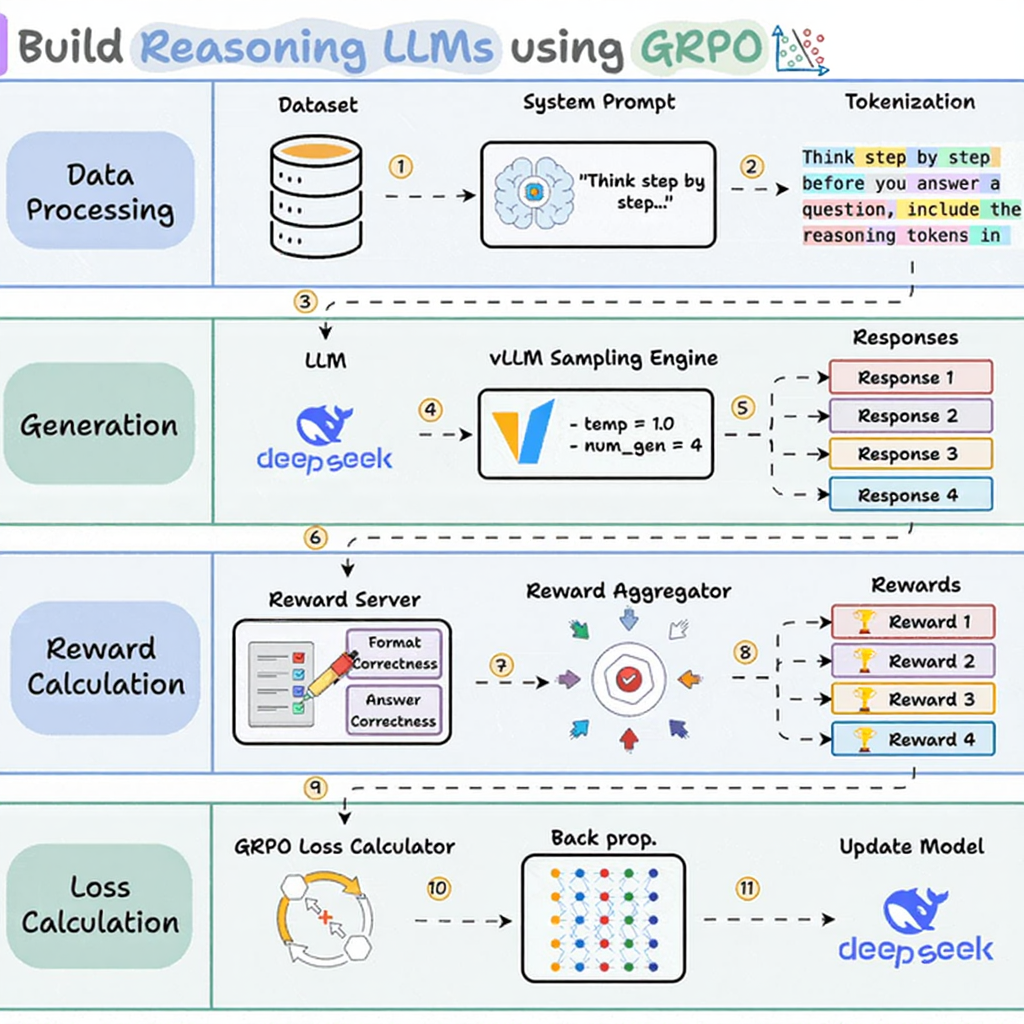
GRPO(组相对策略优化)是目前流行的 RFT 算法。它也是 DeepSeek-R1 推理能力的驱动算法。
其核心思想很简单。GRPO 不训练单独的模型来对答案进行评分,而是生成多个答案,并对它们进行相对评分。
以下是每个提示的具体操作方法:
-
抽样分组:根据当前模型生成 N 个补全结果
-
每次尝试都需评分:奖励函数会对每次尝试进行评估。
-
组内标准化:计算相对于组平均值的相对优势
-
更新模型:强化高于平均水平的行为,抑制低于平均水平的行为。
GRPO只需要相对排名,不需要绝对分数。完成分数是0.3、0.5和0.7,还是30、50和70,都无关紧要。只有排名顺序才能驱动学习。
ART:特工强化训练器
GRPO 功能强大,但如何将其实际应用于实际场景的Agents呢?
ART(代理强化训练器)是一种
这样一来,GRPO 就可以应用于任何 Python 应用程序了。
大多数强化学习框架都是为简单的聊天机器人交互而设计的:一个输入,一个输出,任务就完成了。而真正的智能体则截然不同。它们需要搜索文档、调用API,并经过多步骤推理才能得出答案。
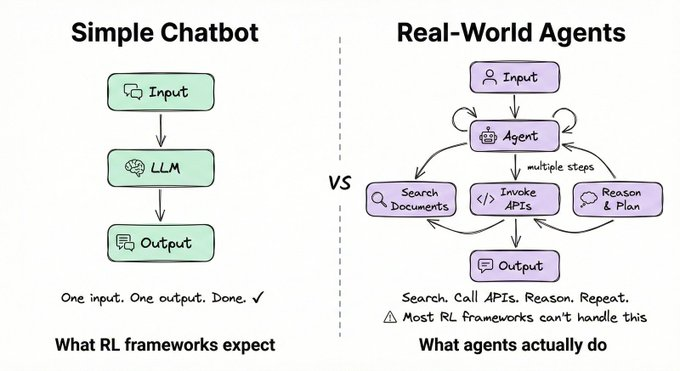
ART 正是为此而生的。它提供:
-
原生支持工具调用和多轮对话
-
与 LangGraph、CrewAI 和 ADK 集成
-
在训练过程中高效利用 GPU
Architecture
ART分为两部分:客户端和后端。
客户端是运行代理代码的地方。它向后端发送推理请求,并将每个操作记录到轨迹中,轨迹是代理一次运行的完整历史记录。
后端是处理繁重任务的地方。它运行vLLM进行快速推理,并运行基于 Unsloth 的 GRPO进行训练。每次训练步骤完成后,一个新的 LoRa 检查点都会自动加载到推理服务器中。
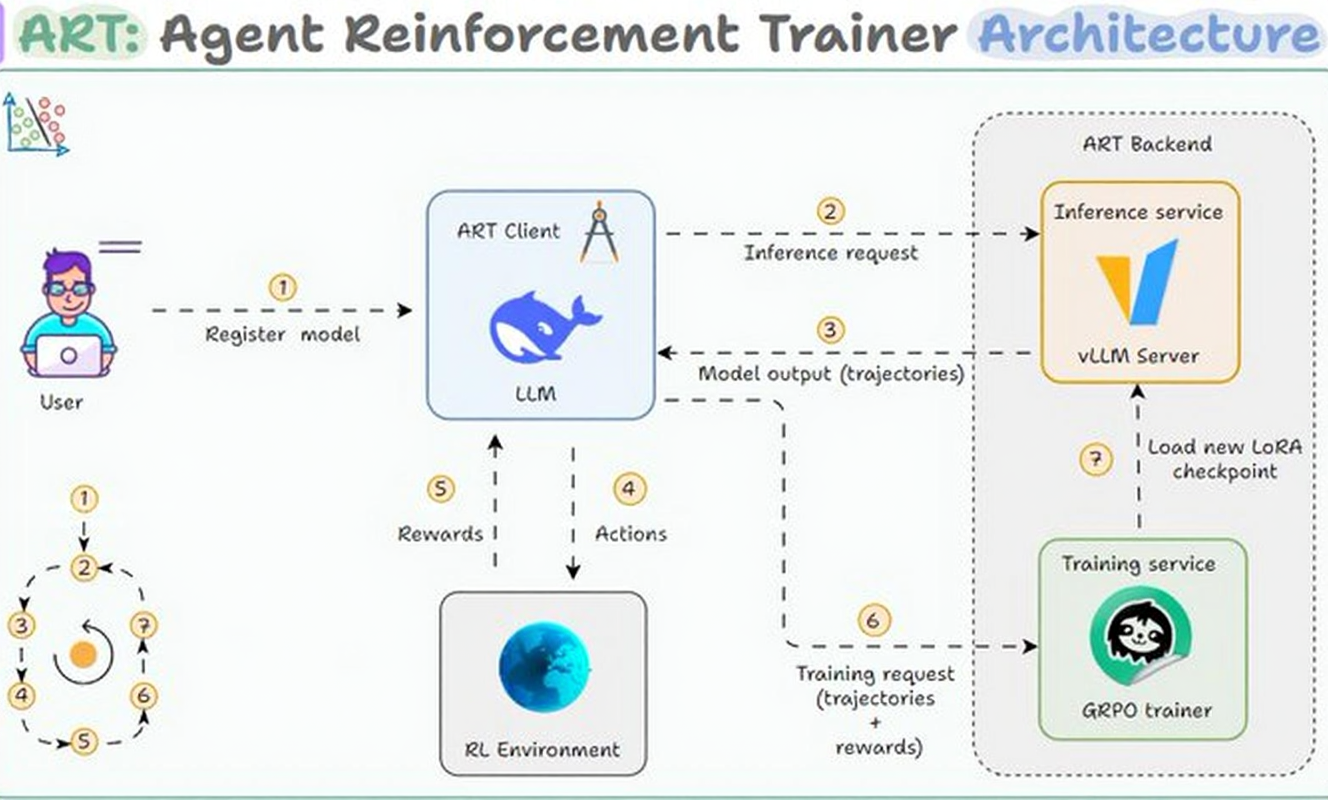
完整的训练循环流程如下:
-
客户端发送推理请求
-
后端生成模型输出
-
代理在环境中执行操作(工具调用、搜索等)
-
环境会带来奖励
-
训练器通过 GRPO 更新模型
-
一个新的 LoRa 检查点加载到推理服务器中
-
重复上述步骤,每次循环模型都会比之前略有改进。
RULER:不再需要手动奖励功能
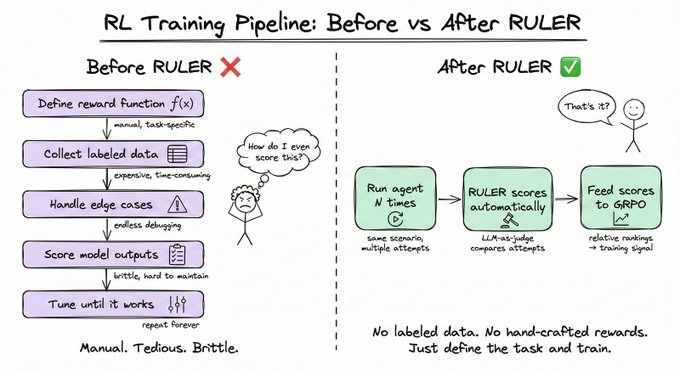
接下来是大多数人最害怕的部分。
定义一个好的奖励函数一直是强化学习中最难的部分。训练邮件代理需要带标签的正确答案,训练代码代理需要测试套件。它们各自都是独特的工程项目。
RULER(相对通用LLM引发的奖励)彻底消除了这一瓶颈。它使用LLM作为评判者来比较多个智能体轨迹并对其进行排序,无需任何标记数据。
它的有效性源于两个关键洞察:
-
要求一位LLM"给这个打分,0-10分"会得到不一致的结果。
-
问"这四次尝试中哪一次最能达到目标?"要可靠得多。
由于 GRPO 只需要相对分数,所以绝对值并不重要。
该过程分为三个步骤:
-
针对某一场景生成 N 条轨迹
-
将它们交给一位LLM评委,由评委对每道题进行0到1分的评分。
-
在 GRPO 中,直接将这些分数用作奖励。
无需编写奖励函数。无需收集带标签的数据。
整合起来:一个实际例子
开发者编写了一个功能齐全的notebook,通过强化学习和 ART 训练 3B 模型,使其掌握如何使用任何 MCP server。
只需提供 MCP server URL 笔记本即可执行以下操作:
-
查询服务器工具
-
生成一组使用这些工具的输入任务
-
使用自动 RULER 评估在这些任务上训练模型
可以在 ART GitHub 仓库中找到更多可供参考的示例,以便进行调整和入门。
(喜欢记得收藏、点赞+关注💗博然AI笔记)